1.背景
缓存架构:
①先查询缓存,判断缓存中是否有数据。
②如果有数据,直接返回。
③如果缓存为空,需要再查一次数据库,并将数据格式异构化,然后预热到缓冲中,然后将结果返回。
问题:
①缓存击穿:缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
②缓存穿透:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
2.布隆过滤器(Bloom Filter)
一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
2.1 如何解决缓存穿透
将存在的值建立一个高效的检索。每次缓存取值时,先走一次判空检索。要求:快速检索+内存空间要非常小
2.2 布隆过滤器如何构建
布隆过滤器本质上是一个 n 位的二进制数组,用0和1表示,二进制数组初始化的时候默认都是0。
假如我们以商品为例,有三件商品,商品编码分别为,id1、id2、id3
a)首先,对id1,进行三次哈希,并确定其在二进制数组中的位置。
假如对id13次hash,分别对应数组中的下标位置“2,5,8”,那么将二进制数组下标位置“2,5,8”的值变成1
b)同理,对id2,进行三次哈希,并确定其在二进制数组中的位置“2,7,98”。
那么将二进制数组下标位置“2,7,98”的值变成1(如果在 Hash 后,原始位它是 0 的话,将其从 0 变为 1;如果本身这一位就是 1 的话,则保持不变。)
2.3 布隆过滤器如何使用
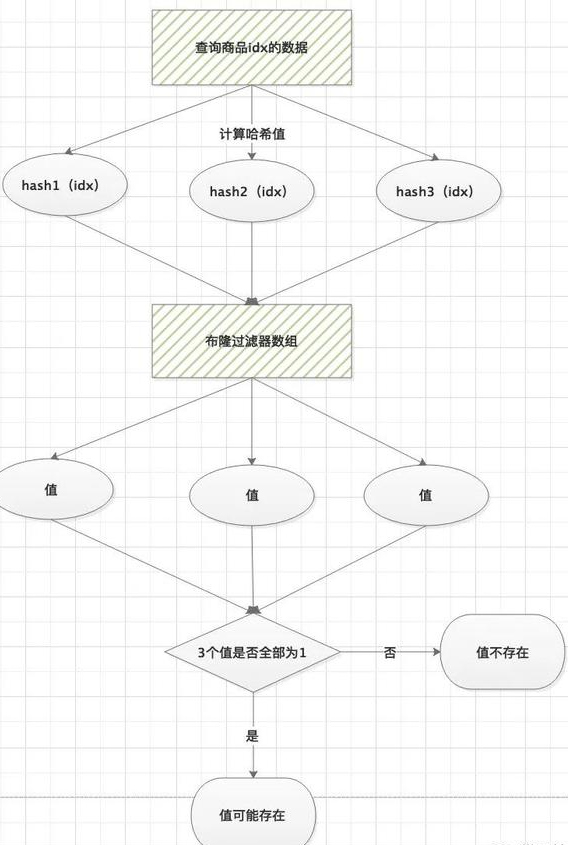
跟初始化的过程类似,当查询一件商品的缓存信息时,我们首先要判断这件商品是否存在。
通过三个哈希函数对商品id计算哈希值然后,在布隆数组中查找访问对应的位值,0或1判断,三个值中,只要有一个不是1,那么我们认为数据是不存在的。注意:布隆过滤器只能精确判断数据不存在情况,对于存在我们只能说是可能,因为存在Hash冲突情况,当然这个概率非常低。
2.4 布隆过滤器如何减少误判
a)增加二进制位数组的长度。这样经过hash后数据会更加的离散化,出现冲突的概率会大大降低
b)增加Hash的次数,变相的增加数据特征,特征越多,冲突的概率越小
c)当然增加数组长度和Hash次数的同时要考虑对性能带来的影响
2.5 Java中使用布隆过滤器
使用Redisson 的组件,内置了布隆过滤器(redis bitmap)
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>xxx</version>
</dependency>RBloomFilter bloomFilter = redissonClient.getBloomFilter("test");
// 初始化布隆过滤器,预计统计元素数量为10000,期望误差率为0.03
bloomFilter.tryInit(10000L, 0.03);
bloomFilter.add("desk");
bloomFilter.add("book");
boolean b1 = bloomFilter.contains("a");
boolean b2 = bloomFilter.contains("desk");2.5 布隆过滤器二进制数组如何进行删除
不能直接删除,因为hash冲突的可能,直接删除可能造成误删
可以创建一个与布隆过滤器二进制数组等长的数组,存储计数器,主要解决冲突问题,每次删除时对应的计数器减一,如果结果为0,更新主数组的二进制值为0
2.6 布隆过滤器总结
是一个很长的二进制向量,主要用于判断一个元素是否在一个集合中
优点:空间效率和查询时间都远远超过一般的算法。
缺点:有一定的误识别率,删除困难。
注意:本文归作者所有,转载请标明出处 http://blog.appcnd.com/post/article4df390485949e4d5
